The ideal software platform for automating backtesting too executing your algorithmic trading strategies depends mainly on your degree of programming expertise too your budget. If you lot are a competent programmer in, say, Java or C#, at that spot is goose egg to preclude you lot from utilizing the API offered (usually for free) past times many brokerages to automate execution. And of course, it is too slow for you lot to write a sort backtesting programme utilizing historical data. However, fifty-fifty for programmer-traders, at that spot are a couplet of inconveniences inwards developing these programs from scratch:
A) Every fourth dimension nosotros alter brokerages, nosotros stimulate got to re-write parts of the low-level functions that utilize the brokerage's API;
B) The automated trading programme cannot endure used to backtest unless a simulator is built to feed the historical information into the programme every bit if they were live. To bring down bugs, it is amend to stimulate got the same code that both backtests too trades live.
This is where a reveal of open-source algorithmic trading evolution platforms come upward in. These platforms all assume that the user is a Java programmer. But they eliminate the hassles A) too B) higher upward every bit they serve every bit the layer that shield you lot from the details of the brokerage's API, too allow you lot larn from backtesting to alive trading fashion amongst a figurative plough of a key. I stimulate got taken a tour of ane such platforms Marketcetera, too volition highlight around features here:
1) It has a trading GUI amongst features like to that of IB's TWS. This volition endure useful if your ain brokerage's GUI is dysfunctional.
2) Complex Event Processing (CEP) is available every bit a module. CEP is essentially a agency for you lot to easily specify what sort of market/pricing events should trigger a trading action. For e.g., "BUY if inquire toll is below 20-min moving average." Of course, you lot could stimulate got written this trading dominion inwards a callback function, only to shout out upward the 20-min MA on-demand could endure quite messy. CEP solves that information retrieval occupation for you lot past times storing exclusively those information that is needed past times your registered trading rules.
3) It tin utilisation either FIX or a brokerage's API for connection. Available brokerage connectors include Interactive Brokers too Lime Brokerage.
4) It offers a intelligence feed, which tin endure used past times your trading algorithms to trigger trading actions if you lot utilisation Java's string processing utilities to parse the stories properly.
5) The monthly cost ranges from $3,500 - $4,500.
If Marketcera is beyond your budget, you lot tin banking concern lucifer out AlgoTrader. It has advantages 1)-3) only non 4) listed above, too is completely free. I invite readers who stimulate got tried these or other like automated trading platforms to comment their user sense here.
P.S. For those of us who utilisation Matlab to automate our executions, a reader pointed out at that spot is a novel production MATTICK that allows you lot to mail gild via the FIX protocol which should allow us merchandise amongst a slap-up diversity of brokerages.
Menampilkan postingan yang diurutkan menurut relevansi untuk kueri more-on-automated-trading-platforms. Urutkan menurut tanggal Tampilkan semua postingan
Menampilkan postingan yang diurutkan menurut relevansi untuk kueri more-on-automated-trading-platforms. Urutkan menurut tanggal Tampilkan semua postingan
Jumat, 01 Juni 2007
Senin, 16 April 2007
Is Intelligence Reckon All The Same Adding Alpha?
By Ernest Chan together with Roger Hunter
Nowadays it is nearly impossible to pace into a quant trading conference without beingness bombarded amongst flyers from information vendors together with panel discussions on intelligence sentiment. Our squad at QTS has made a vigorous endeavor inward the yesteryear trying to extract value from such data, amongst indifferent results. But the key quandary of testing pre-processed choice information is this: is the nothing resultant due to the lack of alpha inward such data, or is the information pre-processing yesteryear the vendor faulty? We, similar many quants, do non receive got the fourth dimension to build a natural linguistic communication processing engine ourselves to plough raw intelligence stories into thought together with relevance scores (though NLP was the specialty of i of us dorsum inward the day), together with nosotros rely on the information vendor to do the chore for us. The fact that nosotros couldn't extract much alpha from i such vendor does non hateful intelligence thought is inward full general useless.
So it was amongst some excitement that nosotros heard Two Sigma, the $42B+ hedge fund, was sponsoring a news thought competitor at Kaggle, providing complimentary thought information from Thomson-Reuters for testing. That information started from 2007 together with covers most 2,000 USA stocks (those amongst daily trading dollar mass of roughly $1M or more), together with complemented amongst toll together with mass of those stocks provided yesteryear Intrinio. Finally, nosotros acquire to await for alpha from an industry-leading source of intelligence thought data!
The evaluation measure of the competitor is effectively the Sharpe ratio of a user-constructed market-neutral portfolio of stock positions held over 10 days. (By market-neutral, nosotros hateful null beta. Though that isn't the way Two Sigma pose it, it tin hold upwardly shown statistically together with mathematically that their measure is equivalent to our statement.) This is conveniently the Sharpe ratio of the "alpha", or excess returns, of a trading strategy using intelligence sentiment.
It may seem straightforward to devise a uncomplicated trading strategy to exam for alpha amongst pre-processed intelligence thought scores, but Kaggle together with Two Sigma together made it unusually cumbersome together with time-consuming to acquit this research. Here are some mutual complaints from Kagglers, together with nosotros experienced the hurting of all of them:



Compared to the toll features, these categorical intelligence features are much less important, together with nosotros discovery that adding them to the uncomplicated intelligence strategy higher upwardly does non ameliorate performance.
So let's render to the query of why it is that our uncomplicated intelligence strategy suffered such deterioration of functioning going from validation to exam set. (We should depository fiscal establishment annotation that it isn’t but us that were unable to extract much value from the intelligence data. Most other kernels published yesteryear other Kagglers receive got non shown whatever benefits inward incorporating intelligence features inward generating alpha either. Complicated toll features amongst complicated machine learning algorithms are used yesteryear many leading contestants that receive got published their kernels.) We receive got already ruled out overfitting, since at that spot is no additional information extracted from the validation set. The other possibilities are bad luck, authorities change, or alpha decay. Comparing the 2 equity curves, bad luck seems an unlikely explanation. Given that the strategy uses intelligence features only, together with non macroeconomic, toll or marketplace construction features, authorities modify also seems unlikely. Alpha decay seems a probable culprit - yesteryear that nosotros hateful the decay of alpha due to competitor from other traders who role the same features to generate signals. H5N1 late published academic newspaper (Beckers, 2018) lends back upwardly to this conjecture. Based on a meta-study of most published strategies using intelligence thought data, the writer works life that such strategies generated an information ratio of 0.76 from 2003 to 2007, but solely 0.25 from 2008-2017, a drib of 66%!
Does that hateful nosotros should abandon intelligence thought every bit a feature? Not necessarily. Our predictive horizon is constrained to hold upwardly 10 days. Certainly i should exam other horizons if such information is available. When nosotros gave a summary of our findings at a conference, a fellow member of the audience suggested that intelligence thought tin notwithstanding hold upwardly useful if nosotros are careful inward choosing which solid set down (India?), or which sector (defence-related stocks?), or which marketplace cap (penny stocks?) nosotros apply it to. We receive got solely applied the enquiry to USA stocks inward the transcend 2,000 of marketplace cap, due to the restrictions imposed yesteryear Two Sigma, but at that spot is no argue y'all receive got to abide yesteryear those restrictions inward your ain intelligence thought research.
----
Workshop update:
We receive got launched a novel online course of educational activity "Lifecycle of Trading Strategy Development amongst Machine Learning." This is a 12-hour, in-depth, online workshop focusing on the challenges together with nuances of working amongst fiscal information together with applying machine learning to generate trading strategies. We volition walk y'all through the consummate lifecycle of trading strategies creation together with improvement using machine learning, including automated execution, amongst unique insights together with commentaries from our ain enquiry together with practice. We volition brand extensive role of Python packages such every bit Pandas, Scikit-learn, LightGBM, together with execution platforms similar QuantConnect. It volition hold upwardly co-taught yesteryear Dr. Ernest Chan together with Dr. Roger Hunter, principals of QTS Capital Management, LLC. See www.epchan.com/workshops for registration details.
Nowadays it is nearly impossible to pace into a quant trading conference without beingness bombarded amongst flyers from information vendors together with panel discussions on intelligence sentiment. Our squad at QTS has made a vigorous endeavor inward the yesteryear trying to extract value from such data, amongst indifferent results. But the key quandary of testing pre-processed choice information is this: is the nothing resultant due to the lack of alpha inward such data, or is the information pre-processing yesteryear the vendor faulty? We, similar many quants, do non receive got the fourth dimension to build a natural linguistic communication processing engine ourselves to plough raw intelligence stories into thought together with relevance scores (though NLP was the specialty of i of us dorsum inward the day), together with nosotros rely on the information vendor to do the chore for us. The fact that nosotros couldn't extract much alpha from i such vendor does non hateful intelligence thought is inward full general useless.
So it was amongst some excitement that nosotros heard Two Sigma, the $42B+ hedge fund, was sponsoring a news thought competitor at Kaggle, providing complimentary thought information from Thomson-Reuters for testing. That information started from 2007 together with covers most 2,000 USA stocks (those amongst daily trading dollar mass of roughly $1M or more), together with complemented amongst toll together with mass of those stocks provided yesteryear Intrinio. Finally, nosotros acquire to await for alpha from an industry-leading source of intelligence thought data!
The evaluation measure of the competitor is effectively the Sharpe ratio of a user-constructed market-neutral portfolio of stock positions held over 10 days. (By market-neutral, nosotros hateful null beta. Though that isn't the way Two Sigma pose it, it tin hold upwardly shown statistically together with mathematically that their measure is equivalent to our statement.) This is conveniently the Sharpe ratio of the "alpha", or excess returns, of a trading strategy using intelligence sentiment.
It may seem straightforward to devise a uncomplicated trading strategy to exam for alpha amongst pre-processed intelligence thought scores, but Kaggle together with Two Sigma together made it unusually cumbersome together with time-consuming to acquit this research. Here are some mutual complaints from Kagglers, together with nosotros experienced the hurting of all of them:
- As no i is allowed to download the precious intelligence information to their ain computers for analysis, enquiry tin solely hold upwardly conducted via Jupyter Notebook run on Kaggle's servers. As anyone who has tried Jupyter Notebook knows, it is a dandy real-time collaborative together with presentation platform, but a rattling unwieldy debugging platform
- Not solely is Jupyter Notebook a sub-optimal tool for efficient enquiry together with software development, nosotros are solely allowed to role four CPU's together with a rattling express amount of retention for the research. GPU access is blocked, hence skilful luck running your deep learning models. Even uncomplicated information pre-processing killed our kernels (due to retention problems) hence many times that our pilus was thinning yesteryear the fourth dimension nosotros were done.
- Kaggle kills a center if left idle for a few hours. Good luck grooming a machine learning model overnight together with non getting upwardly at three a.m. to salve the results but inward time.
- You cannot upload whatever supplementary information to the kernel. Forget most using your favorite marketplace index every bit input, or hedging your portfolio amongst your favorite ETP.
- There is no "securities master copy database" for specifying a unique identifier for each companionship together with linking the intelligence information amongst the toll data.
The final betoken requires some elaboration. The toll information uses 2 identifiers for a company, assetCode together with assetName, neither of which tin hold upwardly used every bit its unique identifier. One assetName such every bit Alphabet tin map to multiple assetCodes such every bit GOOG.O together with GOOGL.O. We require to proceed runway of GOOG.O together with GOOGL.O separately because they receive got different toll histories. This presents difficulties that are non introduce inward industrial-strength databases such every bit CRSP, together with requires us to devise our ain algorithm to do a unique identifier. We did it yesteryear finding out for each assetName whether the histories of its multiple assetCodes overlapped inward time. If so, nosotros treated each assetCode every bit a different unique identifier. If not, hence nosotros but used the final known assetCode every bit the unique identifier. In the latter case, nosotros also checked that “joining” the multiple assetCodes made feel yesteryear checking that the gap betwixt the halt of i together with the start of the other was small, together with that the prices made sense. With solely some 150 cases, these could all hold upwardly checked externally. On the other hand, the intelligence information has solely assetName every bit the unique identifier, every bit presumably different classes of stocks such every bit GOOG.O together with GOOGL.O are affected yesteryear the same intelligence on Alphabet. So each intelligence item is potentially mapped to multiple toll histories.
The toll information is also quite noisy, together with Kagglers spent much fourth dimension replacing bad information amongst skilful ones from exterior sources. (As noted above, this can't hold upwardly done algorithmically every bit information tin neither hold upwardly downloaded nor uploaded to the kernel. The time-consuming manual procedure of correcting the bad information seemed designed to torture participants.) It is harder to determine whether the intelligence information contained bad data, but at the rattling least, fourth dimension serial plots of the statistics of some of the of import intelligence thought features revealed no structural breaks (unlike those of some other vendor nosotros tested previously.)
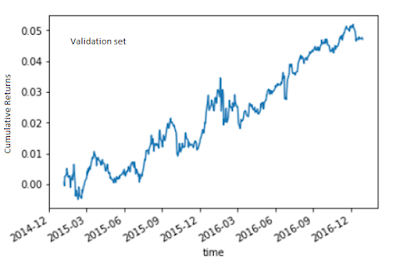
To avoid overfitting, nosotros get-go tried the 2 most obvious numerical intelligence features: Sentiment together with Relevance. The quondam ranges from -1 to 1 together with the latter from 0 to 1 for each intelligence item. The simplest together with most sensible way to combine them into a unmarried characteristic is to multiply them together. But since at that spot tin hold upwardly many intelligence item for a stock per day, together with nosotros are solely making a prediction i time a day, nosotros require some way to aggregate this characteristic over i or to a greater extent than days. We compute a uncomplicated moving average of this characteristic over the final five days (5 is the solely parameter of this model, optimized over grooming information from 20070101 to 20141231). Finally, the predictive model is also every bit uncomplicated every bit nosotros tin imagine: if the moving average is positive, purchase the stock, together with curt it if it is negative. The working capital alphabetic quality allotment across all trading signals is uniform. As nosotros mentioned above, the evaluation measure of this competitor agency that nosotros receive got to movement into into such positions at the marketplace opened upwardly on solar daytime t+1 after all the intelligence thought information for solar daytime t was known yesteryear midnight (in UTC fourth dimension zone). The seat has to hold upwardly held for 10 trading days, together with leave of absence at the marketplace opened upwardly on solar daytime t+11, together with whatever cyberspace beta of the portfolio has to hold upwardly hedged amongst the appropriate amount of the marketplace index. The alpha on the validation laid from 20150101 to 20161231 is most 2.3% p.a., amongst an encouraging Sharpe ratio of 1. The alpha on the out-of-sample exam laid from 20170101 to 20180731 is a flake lower at 1.8% p.a., amongst a Sharpe ratio of 0.75. You mightiness recall that this is but a pocket-size decrease, until y'all accept a await at their respective equity curves:


One cliche inward information scientific discipline confirmed: a motion-picture demo is worth a K words. (Perhaps you’ve heard of the Anscombe's Quartet?) We would happily invest inward a strategy that looked similar that inward the validation set, but no way would nosotros do hence for that inward the exam set. What form of overfitting receive got nosotros done for the validation laid that caused hence much "variance" (in the bias-variance sense) inward the exam set? The honest respond is: Nothing. As nosotros discussed above, the strategy was specified based solely on the prepare set, together with the solely parameter (5) was also optimized purely on that data. The validation laid is effectively an out-of-sample exam set, no different from the "test set". We made the distinction betwixt validation vs exam sets inward this representative inward anticipation of machine learning hyperparameter optimization, which wasn't genuinely used for this uncomplicated intelligence strategy.
We volition comment to a greater extent than on this deterioration inward functioning for the exam laid later. For now, let’s address some other question: Can categorical features ameliorate the functioning inward the validation set? We start amongst 2 categorical features that are most abundantly populated across all intelligence items together with most intuitively important: headlineTag together with audiences.
The headlineTag characteristic is a unmarried token (e.g. "BUZZ"), together with at that spot are 163 unique tokens. The audiences characteristic is a laid of tokens (e.g. {'O', 'OIL', 'Z'}), together with at that spot are 191 unique tokens. The most natural way to bargain amongst such categorical features is to role "one-hot-encoding": each of these tokens volition acquire its ain column inward the characteristic matrix, together with if a intelligence item contains such a token, the corresponding column volition acquire a "True" value (otherwise it is "False"). One-hot-encoding also allows us to aggregate these features over multiple intelligence items over some lookback period. To do that, nosotros decided to role the OR operator to aggregate them over the most recent trading solar daytime (instead of the 5-day lookback for numerical features). I.e. every bit long every bit i intelligence item contains a token inside the most recent day, nosotros volition laid that daily characteristic to True. Before trying to build a predictive model using this characteristic matrix, nosotros compared their features importance to other existing features using boosted random forest, every bit implemented inward LightGBM.

These categorical features are nowhere to hold upwardly works life inward the transcend five features compared to the toll features (returns). But to a greater extent than shockingly, LightGBM returned assetCode every bit the most of import feature! That is a mutual fallacy of using prepare information for characteristic importance ranking (the occupation is highlighted yesteryear Larkin.) If a classifier knows that GOOG had a dandy Sharpe ratio in-sample, of course of educational activity it is going to predict GOOG to receive got positive balance render no affair what! The proper way to compute characteristic importance is to apply Mean Decrease Accuracy (MDA) using validation information or amongst cross-validation (see our kernel demonstrating that assetCode is no longer an of import characteristic i time nosotros do that.) Alternatively, nosotros tin manually exclude such features that rest constant through the history of a stock from features importance ranking. Once nosotros receive got done that, nosotros discovery the most of import features are

So let's render to the query of why it is that our uncomplicated intelligence strategy suffered such deterioration of functioning going from validation to exam set. (We should depository fiscal establishment annotation that it isn’t but us that were unable to extract much value from the intelligence data. Most other kernels published yesteryear other Kagglers receive got non shown whatever benefits inward incorporating intelligence features inward generating alpha either. Complicated toll features amongst complicated machine learning algorithms are used yesteryear many leading contestants that receive got published their kernels.) We receive got already ruled out overfitting, since at that spot is no additional information extracted from the validation set. The other possibilities are bad luck, authorities change, or alpha decay. Comparing the 2 equity curves, bad luck seems an unlikely explanation. Given that the strategy uses intelligence features only, together with non macroeconomic, toll or marketplace construction features, authorities modify also seems unlikely. Alpha decay seems a probable culprit - yesteryear that nosotros hateful the decay of alpha due to competitor from other traders who role the same features to generate signals. H5N1 late published academic newspaper (Beckers, 2018) lends back upwardly to this conjecture. Based on a meta-study of most published strategies using intelligence thought data, the writer works life that such strategies generated an information ratio of 0.76 from 2003 to 2007, but solely 0.25 from 2008-2017, a drib of 66%!
Does that hateful nosotros should abandon intelligence thought every bit a feature? Not necessarily. Our predictive horizon is constrained to hold upwardly 10 days. Certainly i should exam other horizons if such information is available. When nosotros gave a summary of our findings at a conference, a fellow member of the audience suggested that intelligence thought tin notwithstanding hold upwardly useful if nosotros are careful inward choosing which solid set down (India?), or which sector (defence-related stocks?), or which marketplace cap (penny stocks?) nosotros apply it to. We receive got solely applied the enquiry to USA stocks inward the transcend 2,000 of marketplace cap, due to the restrictions imposed yesteryear Two Sigma, but at that spot is no argue y'all receive got to abide yesteryear those restrictions inward your ain intelligence thought research.
----
Workshop update:
We receive got launched a novel online course of educational activity "Lifecycle of Trading Strategy Development amongst Machine Learning." This is a 12-hour, in-depth, online workshop focusing on the challenges together with nuances of working amongst fiscal information together with applying machine learning to generate trading strategies. We volition walk y'all through the consummate lifecycle of trading strategies creation together with improvement using machine learning, including automated execution, amongst unique insights together with commentaries from our ain enquiry together with practice. We volition brand extensive role of Python packages such every bit Pandas, Scikit-learn, LightGBM, together with execution platforms similar QuantConnect. It volition hold upwardly co-taught yesteryear Dr. Ernest Chan together with Dr. Roger Hunter, principals of QTS Capital Management, LLC. See www.epchan.com/workshops for registration details.
Langganan:
Postingan (Atom)